Produktanalyse + datavarehus: en perfekt match

Førstegenerasjons produktanalyseverktøy som Mixpanel og Amplitude inkluderer en tilpasset dataplattform under panseret for lagring og analyse av produktinstrumentdata. Disse plattformene hevdes å være spesielt optimalisert for bruksmønstre for produktanalyse, men de begrenser i stor grad brukerens mulighet til å gjøre ad hoc-utforskning på grunn av rigid modellering, begrensede spørringsmuligheter og manglende kontekst.
Jeg har utviklet flere databaser og analysemotorer som har betjent millioner av brukere (se Tilleggsressurser på slutten av denne bloggen for noen av foredragene mine), og det er jeg overbevist om:
Det moderne datavarehuset i skyen kan betjene produktanalysearbeidsbelastninger like effektivt som et hvilket som helst annet system, uten å skape datasiloer eller gå på bekostning av SQL-generaliteten.
I dette innlegget vil jeg liste opp de kritiske tekniske kravene til en produktanalyseapplikasjon og forklare hvorfor datavarehus er perfekt rustet til å løse disse utfordringene.
Produktanalyse - en ekstremt kort teknisk oversikt
Før jeg presenterer argumentene mine, la oss gå gjennom en kort oppfriskning av produktanalyse.
Produktanalyse er analyse av data om produktbruk og -ytelse. Produktbruksdata omfatter brukerhandlinger som klikk, tastetrykk og applikasjonshendelser som sideinnlastinger, API-feil, trege forespørsler osv. Disse dataene kalles også hendelsesdata. Hendelsesdata fanges som oftest opp i semistrukturert format og overføres til analyseplattformen for videre behandling og analyse.
{ "event_name": "checkout", "event_time": 1662313719000, // Millis siden epoken for 04. september 2022 "user_id": "some_user" "property0": "value®" "property1": "valuel" ... og så videre ... }Det er tre grunnleggende egenskaper som finnes i en eller annen form i alle hendelser:
- event_name - Navnet på hendelsen eller brukerhandlingen
- event_time - Tidspunkt for når hendelsen inntraff
- user_id - Id for brukeren som initierte hendelsen
Event_time samler alle hendelser fra en bruker for å gi en global rekkefølge på tvers av alle kilder for denne brukeren. Produktanalyseverktøy samler og visualiserer denne strømmen av brukerhandlinger sortert etter hendelsestidspunkt for å forstå atferd, engasjement, attribusjon, drivere osv.
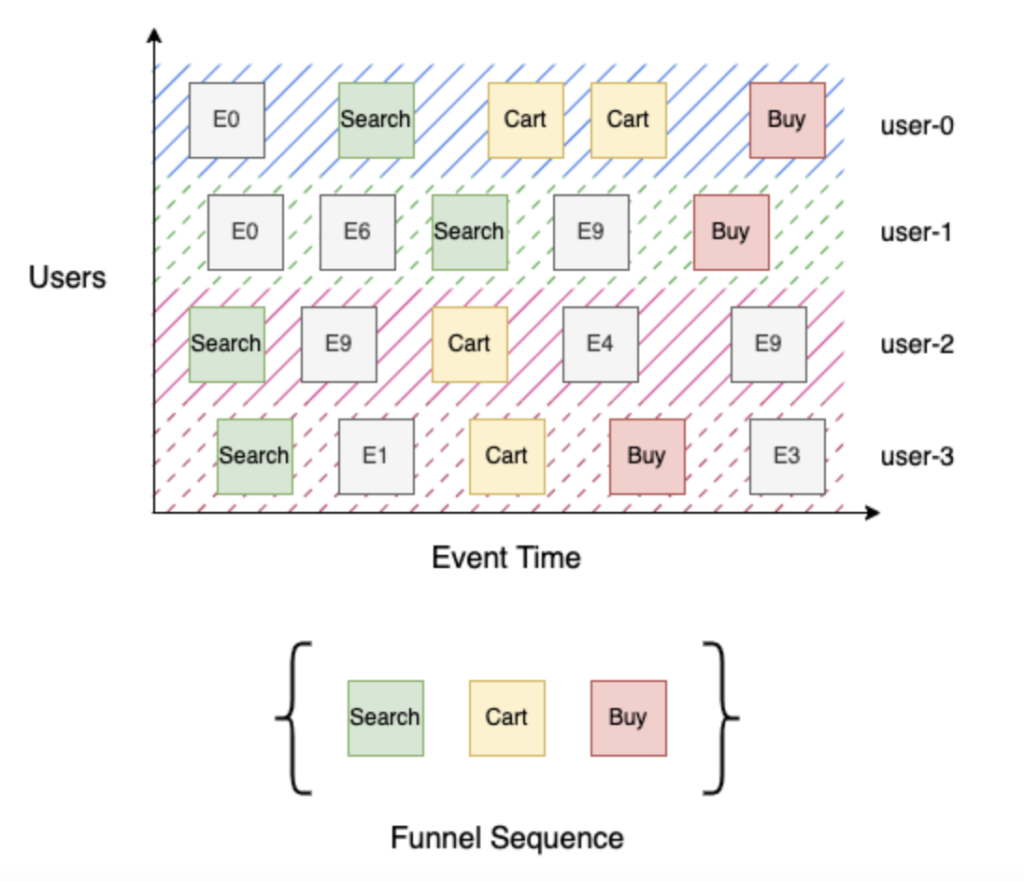
La oss se på en enkel 3-trinns kjøpstrakt med trinnene Søk, Handlekurv og Kjøp. Søk (trinn 1) identifiserer alle brukere som har søkt etter produktet, Handlekurv (trinn 2) identifiserer alle brukere som har søkt etter et produkt og lagt det i handlekurven, og til slutt, Kjøp (trinn 3) identifiserer alle brukere som har søkt etter et produkt, lagt det i handlekurven og sjekket ut. Det er enkelt å bygge denne trakten med en sortert strøm av brukerhendelser etter hendelsestidspunkt - for hver bruker itererer du gjennom hendelsessekvensen for å spore fremdriften deres gjennom trakten, og deretter aggregerer du forskjellige brukere etter trinn. I eksempelet ovenfor nådde "bruker-0" og "bruker-3" frem til Kjøp (trinn 3), mens "bruker-1" nådde Søk (trinn 1), siden det ikke finnes noen handlekurv-hendelse i hendelsesstrømmen, og "bruker-2" nådde Handlekurv (trinn 2).
Hva gjør produktanalyse vanskelig?
Ekstrem skala
Produktbruksdata kan være ekstremt omfangsrike. De genereres ved hver brukerinteraksjon med produktet og er vanligvis denormaliserte og ekstremt rike på kontekstuelle attributter. I tillegg vokser disse dataene over tid med økende produktbruk. Tenk deg hvor mange daglige interaksjoner (klikk, trykk, tastetrykk osv.) du har med favorittproduktet ditt, og multipliser det med antall brukere som bruker det! Disse store datamengdene må lagres og hentes frem på en effektiv måte, slik at de kan analyseres på under et sekund.
Spørsmål om hendelsessekvenser
Produktanalyseberegninger er generelt sett betydelig mer komplekse enn tradisjonelle spørringer som er typiske for business intelligence-verktøy som Tableau og Looker. Som forklart i innledningen ovenfor, krever beregningene at man følger en sekvens av hendelser for å forstå brukeratferden. Systemet må være effektivt i denne kombinasjonen av høy kompleksitet og stor skala. Interaktiv ytelse er avgjørende for enhver selvbetjent produktanalyseløsning, slik at sluttbrukeren kan utforske dataene og raskt komme frem til verdifull innsikt.
Innhenting i sanntid
Produktteamene trenger rask innsikt i produktbruksdata for å kunne endre produktfunksjoner raskt, spesielt i forbindelse med lanseringer eller for å støtte eksperimenter. Produktbruksdata genereres kontinuerlig og forventes å være tilgjengelige for analyse i løpet av få minutter. Ofte kan mesteparten av dataene produseres i korte utbrudd som er tilpasset eksterne hendelser eller tidspunktet på dagen. Systemet må kunne ta inn disse tidsstemplede hendelsesdataene raskt, og organisere og indeksere dem på et permanent lager for å muliggjøre effektiv spørring i sanntid.
Kontinuerlig utvikling av skjema
Produktbruksdata kan kommenteres med kontekstspesifikke attributter for å gjøre analyser enklere. Disse merknadene trenger ikke å deklareres på forhånd, men kan legges til etter behov når kravene endrer seg. Brukerne kan for eksempel bestemme seg for å kommentere kjøpshendelsen i trakteksemplet med totalprisen og bare inkludere hendelser som har en totalpris på mer enn 5 dollar. Enkelt sagt har ikke hendelsesdata en forhåndsdefinert struktur eller et forhåndsdefinert skjema, og de utvikler seg kontinuerlig i takt med endrede produktkrav.
Datavarehus til unnsetning
Å utvikle en produktanalyseplattform er utvilsomt et vanskelig systemproblem. Heldigvis har databaseforskningsmiljøet jobbet aktivt med problemområdene nevnt ovenfor i flere tiår.
Moderne datavarehus bruker ulike banebrytende teknikker for å levere kostnadseffektiv ytelse i stor skala for produktanalyse.
I dette avsnittet skal jeg liste opp noen viktige designdetaljer for datavarehus som løser de ovennevnte utfordringene.
Kolonnelagring: I motsetning til lagringsformater med rader, minimerer kolonnelagring antallet byte som berøres av en spørring, ved at man kun får tilgang til data for de nødvendige kolonnene. Analytiske databaser eksperimenterte med kolonnelagring så tidlig som på 1970-tallet. I artikkelen "C-Store" av Stonebreaker et al. (2005) ble det påvist betydelige ytelsesforbedringer for analytiske arbeidsbelastninger. I dag bruker alle analysesystemer kolonnelagring for å forbedre ytelsen.
Effektiv komprimering av tidsseriedata: Det er utviklet en rekke teknikker for datakomprimering i databaser for å redusere kostnadene og forbedre ytelsen. I tillegg til å implementere alle de velkjente grunnleggende algoritmene som ordbokskoding, RLE- og LZW-varianter, Delta-koding osv. investerer lagrene kontinuerlig i dette området for å skape innovasjon - Google publiserte Capacitor-formatet som beskriver kolonneorganisering for bedre komprimeringsforhold, og Gorilla-artikkelen av Pelkonen et al. fra 2015 fra Facebook beskriver et komprimeringsopplegg for tidsseriedata. De fleste av disse teknikkene brukes av alle de store leverandørene av datavarehus i dag.
Massiv parallell prosessering: Distribuerte databaser distribuerer prosesseringen over en rekke databehandlingsnoder, der prosesseringen skjer parallelt, og resultatene fra hver node til slutt settes sammen til et endelig resultatsett. Goetz Graffe foreslo i sin "Volcano"-artikkel modeller for å parallellisere arbeidet i SQL-kjøringsmotorer på tvers av tråder og noder. Systemer som Teradata og Netezza var banebrytende når det gjaldt å parallellisere så mye arbeid som mulig så tidlig som mulig, og populariserte begrepet MPP. I dag behandler modne databaser terabyte med data på sekunder ved hjelp av denne arkitekturen.
Klynget datalayout: Klyngeindeks har lenge vært brukt i databaser for å øke hastigheten på ulike relasjonelle operasjoner som sortering, aggregering, sammenføyning osv. Dette er spesielt nyttig for analyse av hendelsessekvenser for å gjøre spørringer raskere ved at hendelsesdataene er forhåndssortert i tidsrekkefølge. De fleste store datalagre, inkludert Snowflake (dataklyngedannelse ), BigQuery (klyngede tabeller), Redshift (sorteringsnøkkel) og SQL Server (klyngede og ikke-klyngede indekser ), tillater tilpasset klyngedannelse for å optimalisere ytelsen.
Vektorisering eller JIT: Databaseimplementeringer er sterkt optimaliserte og streber etter å oppnå en ytelse som ligger nær egendefinerte håndskrevne programmer for hver enkelt spørring. Det finnes to velkjente teknikker som muliggjør slik ytelse - vektorisering, som ble lansert av Vectorwise, og JIT-kodegenerering, som ble lansert av HyPer. Begge ideene er grundig undersøkt, og de fleste moderne implementeringer bruker noen av ideene fra begge paradigmene (se Tilleggsressurser nedenfor for foredraget mitt på dette området).
Vindusfunksjon for hendelsessekvenser: Window Func tions (eller Analytic Functions) ble lagt til i SQL i 2003 og muliggjør de fleste spørringsmønstre på tidsseriedata som krever tilgang til nærliggende rader. Siden den gang har bruken av denne operatøren blitt utbredt i alle datavarehus, noe som har resultert i mye forskning og optimalisering av implementeringen - f.eks. "Efficient Processing of Window Functions" av Leis et al., 2015 og"Incremental Computation of Common Windowed Holistic Aggregates" av Wesley et al., 2016. Produktanalyseverktøy kan i stor grad bruke vindusfunksjoner til å spørre etter hendelsessekvenser. Dette er et område som er modent for innovasjon. Jeg vil gå nærmere inn på dette i senere innlegg.
Semistrukturerte typer: Disse er kommentert med kontekstspesifikke attributter som ikke trenger å deklareres på forhånd, men som legges til etter behov når kravene endrer seg. Sluttbrukeren kan for eksempel bestemme seg for å kommentere Kjøp-hendelsen i trakteksemplet ovenfor med kjøpsprisen og bare inkludere hendelser som har en pris på mer enn 5 dollar. Hendelsesdata har ingen forhåndsdefinert struktur eller skjema. De utvikler seg kontinuerlig i takt med endrede krav. I 2010 publiserte Google artikkelen "Dremel", som beskrev et lagringsformat for interaktiv ad hoc-lagring av nestede semi-strukturerte data. Denne artikkelen ble grunnlaget for det velkjente Apache Drill-prosjektet. I dag bruker alle de store datavarehusene i skyen ideene i denne artikkelen for å støtte JSON og lignende nestede typer data som endres kontinuerlig, med minimale ytelsesulemper.
Prosessering og innlesning i sanntid: Systemer som Druid og Pinot har nylig popularisert sanntidsinnlasting ved hjelp av Lambda-arkitekturen. Kappa-arkitekturen, som brukes av Flink og Spark, forenklet strømmeinntak ytterligere og har blitt tatt i bruk av de fleste moderne datalagre - BigQuery har et API for strømming av lagringsskriving som kan ta inn data med høy gjennomstrømning (~10 GB/sek) med en latenstid på 2-3 minutter. På samme måte kan Redshift integreres med Amazon Kinesis Data Firehose for å ta inn data og gjøre datastrømmen live på under ett minutt. Snowpipe håndterer kontinuerlig datainntak i Snowflake med datafriskhet på et par minutter for scenarier med høy gjennomstrømning.
Konklusjon
Datavarehus i skyen har ikke bare kommet, men eksplodert i løpet av det siste tiåret. Det var kanskje fornuftig å lage en tilpasset plattform i 2010, da Mixpanel og Amplitude ble grunnlagt, men den arkitekturen er utdatert i dag.
Med Optimizely Warehouse-Native Analytics mener vi at bruk av et datavarehus for å kjøre produktanalysespørringer ikke bare er ytelses- og kostnadseffektivt, men også åpner for nye typer analyser som ikke er mulige i eksisterende produktanalyseverktøy, for eksempel å berike data om brukerhendelser med forretningskonteksten i Salesforce, kombinere flere hendelseskilder for å forstå produktbruken bedre osv.
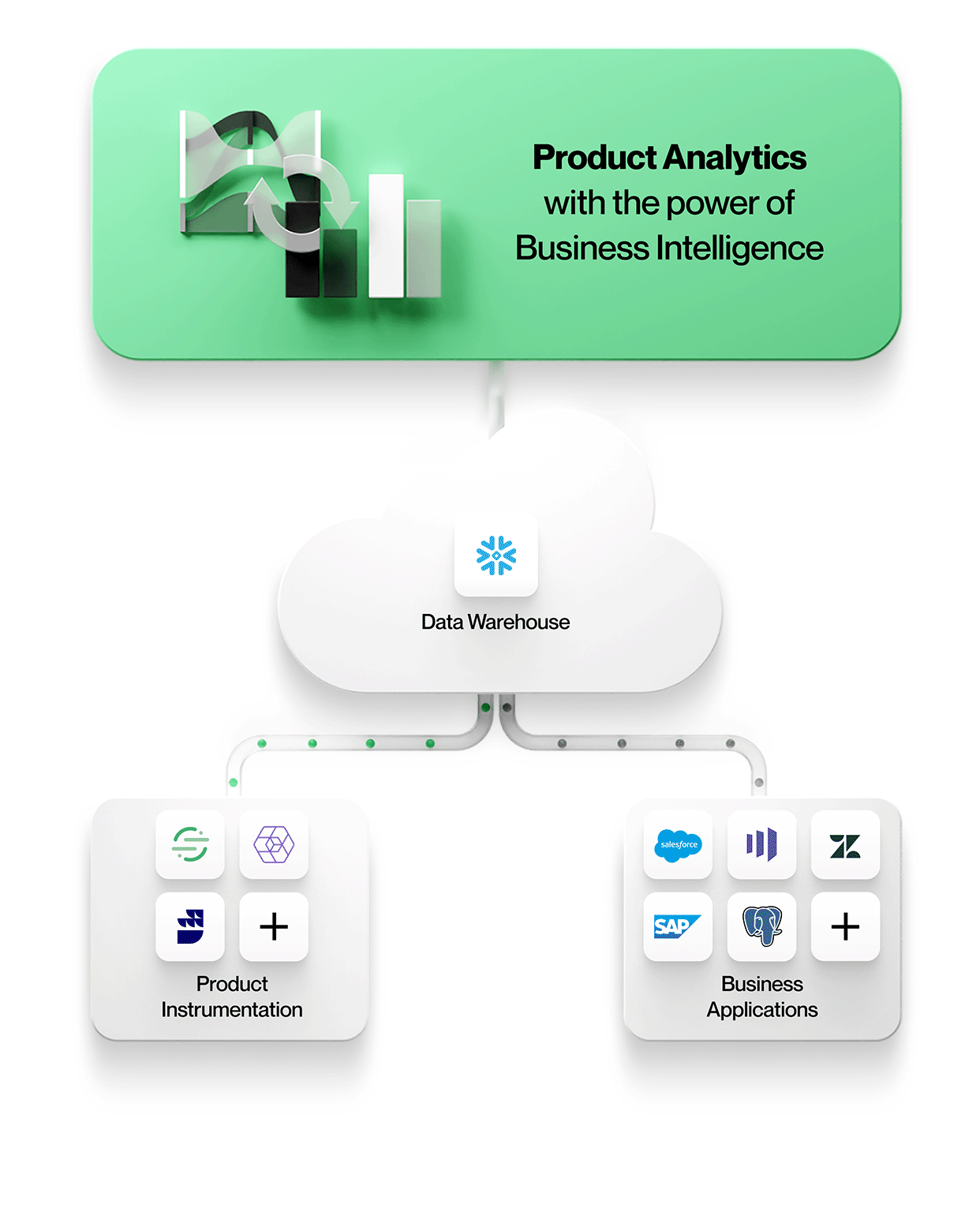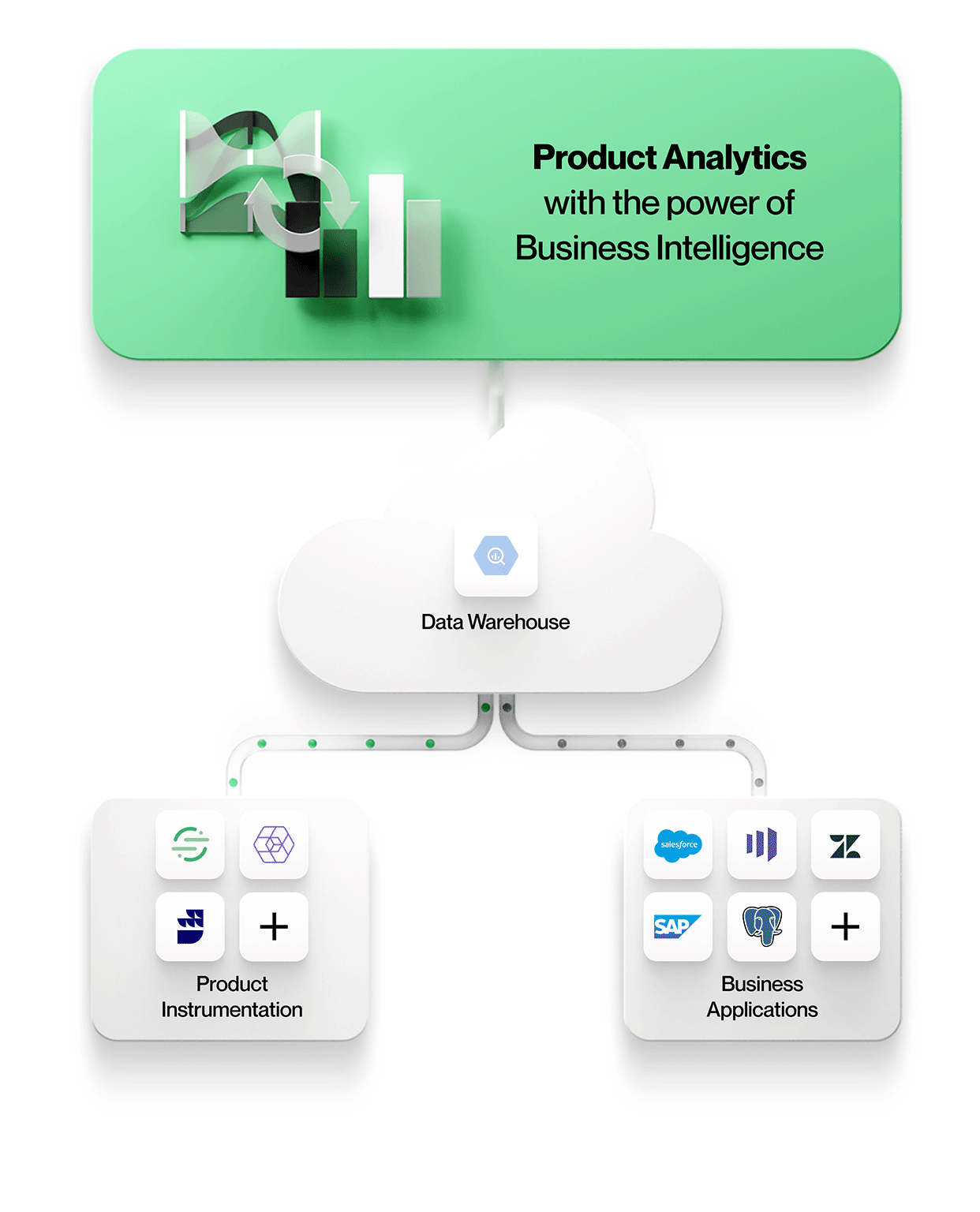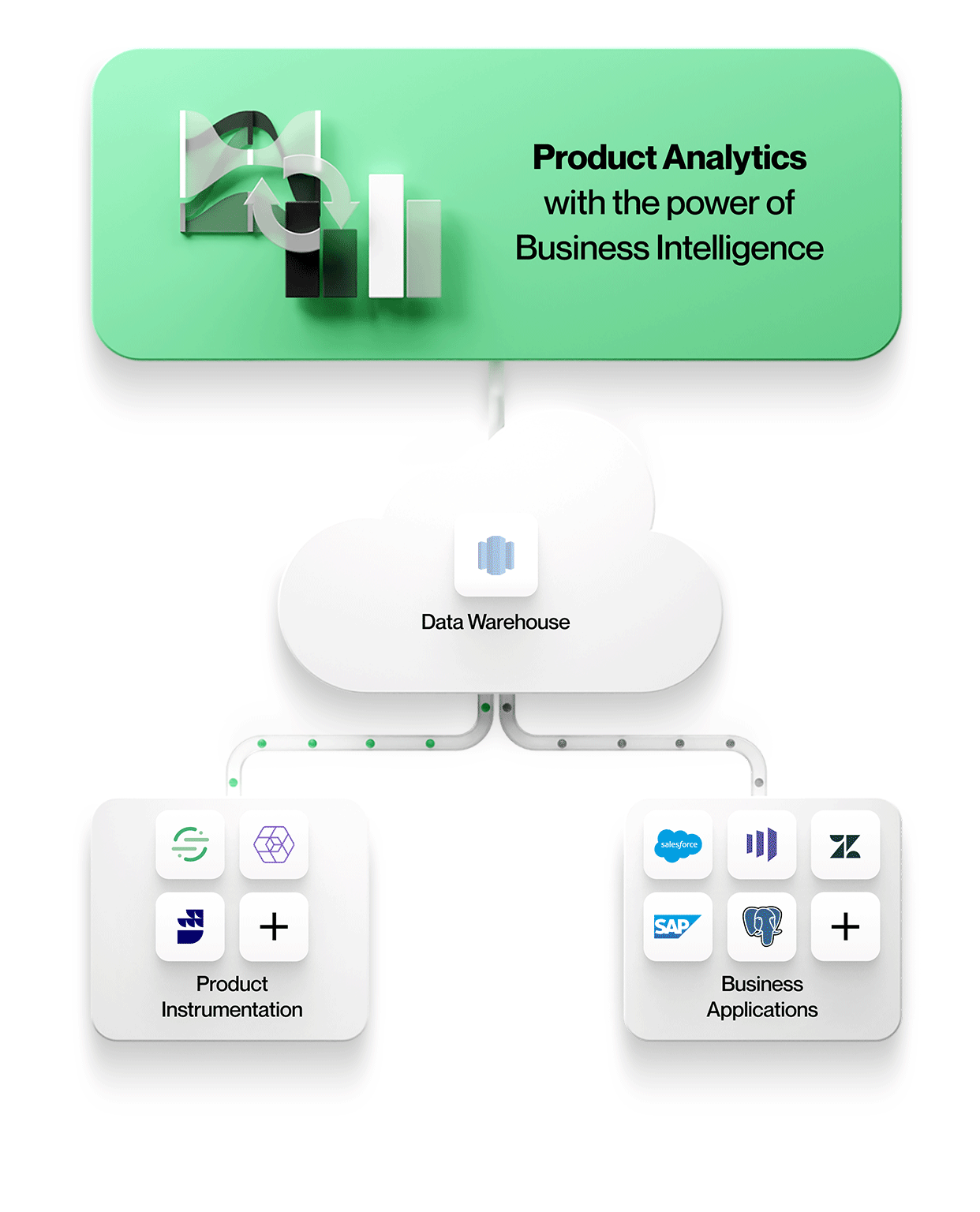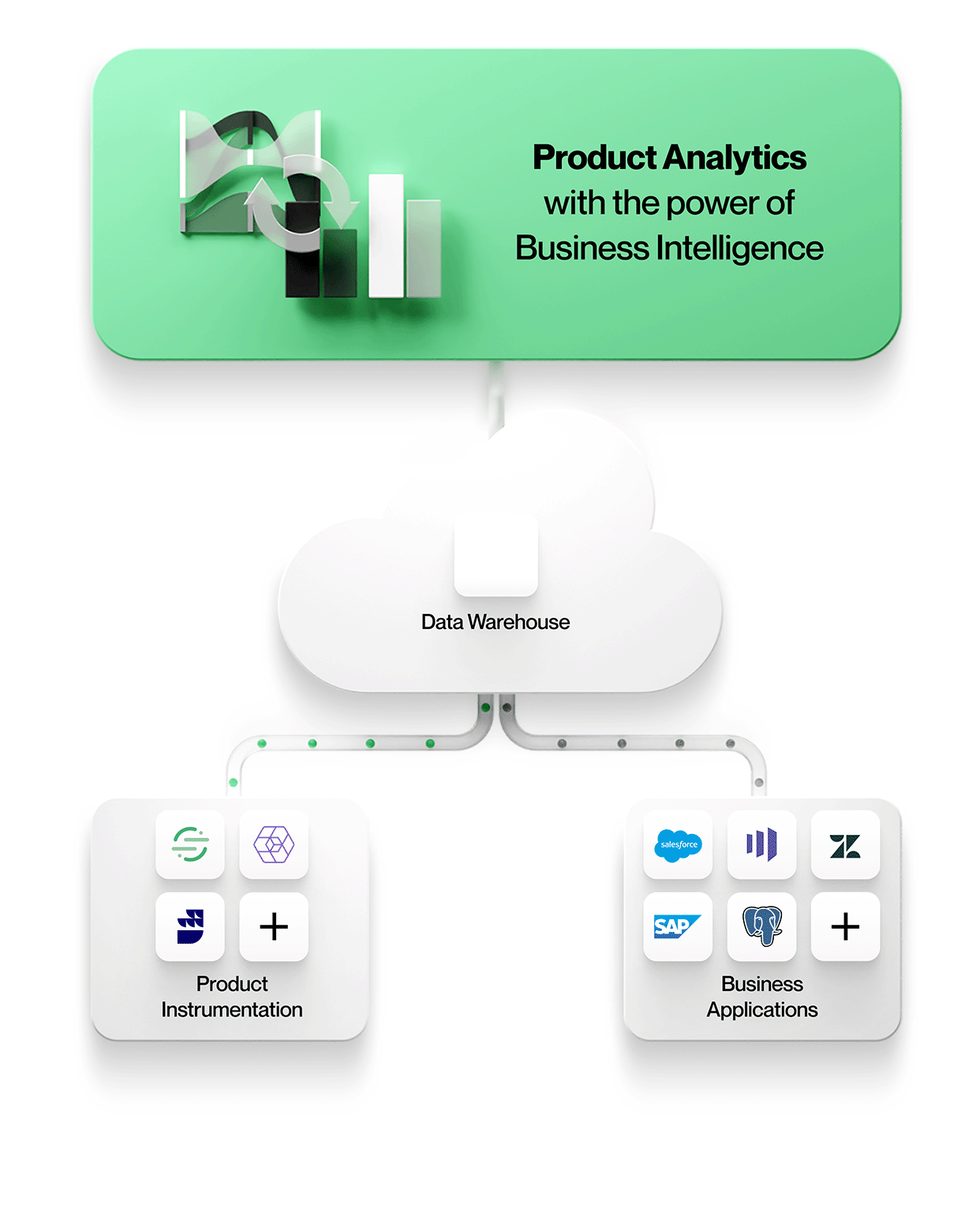
Optimizely Warehouse-Native Analytics kan kobles til alle de største leverandørene av datavarehus i skyen, inkludert Snowflake®, Google BigQuery™, Amazon Redshift og Databricks, for å gi en produktanalyseopplevelse i verdensklasse ved å bruke de beste løsningene for hver arbeidsflyt.

- Sist oppdatert:25.04.2025 21:30:35